
When you want to start a project with data the first concern is to get data. Once you have it you can build fancy graphs, pie charts and ML models, but before that – please be a nice guy/gal and collect the data.
In one of my previous articles I’ve already explained the process of scraping data from a website – what libraries to use, how to browse through the tags etc. That mentioned article is here.
In this one I would like to make a step forward and improve the scraping process by automating it and moving it to the cloud. We will use AWS Lambda and AWS S3 in order to achieve that.
So the idea is to write a Lambda that will be running once a day, collecting the latest data and adding it to the dataset we maintain in S3. Pretty easy, pretty straightforward.
For this we will need to configure: code of the Lambda, cron trigger, role and policy with write permissions and S3 bucket.
S3
Let’s start with the most basic and easy part. If you want to save data on the cloud you have to enable some storage solution. In AWS it is S3. In our case, we just have to create a bucket where we are going to upload scraped data. This is how my bucket looks for example:
Lambda
Our Lambda will use BeatifulSoup and requests in order to access the website, scrape it, reorganize the data for better consumption and upload that data to previously created S3 bucket.
All the code for the scraper and its breakdown can be found in my previous article “Web Scraping Advanced Football Statistics“. Also adding a refactored code adjusted for Lambda execution to my public repository on GitHub. Here I will only pinpoint few alternations that had to be done in order to make that code … – Lambda code.
First, all the code has to go under Lambda’s main function lambda_handler(event, context). And putting all the mess in only one function is not a good idea, so I refactored that mess. Above you have a link with final result.
Second, as we are working on the cloud now we have to save our generated data somewhere. Yes, Lambda has it’s own storage, but it is ephemeral. So the line df.to_csv('filename.csv') won’t really work here. We have to upload our CSV to S3, to a durable storage. There are two ways of doing that – using boto3 with s3_client and its upload methods or use pandas built-in capability to upload files to S3.
With boto3 it is pretty straightforward – you check out documentation for uploading files to S3 and apply one of them. Here I used upload_file()
Also you can just use df.to_csv('s3://destination-bucket/destination/path/to/file') but there is a little pitfall here. In order to use this you have to have library s3fs installed. On your machine it is easy – you just use pip install and done. With Lambda it’s a bit different. You have to create a layer. A layer consists of all the custom code that your Lambda uses during the execution which wasn’t added by AWS developers by default. So if you have custom modules in your function – please be kind and upload them as a layer. In this particular situation, as I was already building a layer for pandas and BeautifulSoup I just added s3fs to it.
How to build a layer? In the end, layer is just a zip with all the libraries you need for your lambda. I just copied the contents from venv/lib/python3.x/site-packages until Lambda stopped complaining about missing modules. This is why the version of layer that worked for me was only 6 XD. For python, structure that worked in my case is:
pandas_layer.zip
\--python
\--numpy
\--numpy.libs
\--numpy-1.19.5.dist-info
\--pandas
\--pandas-1.1.5.dist-info
\--...Permissions
Now, when we have our S3 bucket, our lambda code and layers configured we have to enable communication between Compute and Storage. In AWS we create an IAM role for the Lambda and attach a policy that allows this Lambda to read and write to S3.
AWS recommends usage of minimum allowed permissions for the services. It means, if Lambda needs to read and write to a specific S3 bucket, allow only to do that (don’t give it permission to change S3 parameters for example) and only to that specific S3 bucket (no need to give access to entire S3).
Normally you would add a standard role for Lambda execution like “AWSLambdaBasicExecutionRole” and also attach an additional custom policy specific for your needs. In this case we add a policy to read and write to S3.
Now our Lambda can write to S3! Yuuhhuu!
Triggers
Well, we can launch our lambda manually or we can configure it to execute automatically based on certain events. Those events can be anything: from creating an object in S3 to finishing an ETL job to creation of new EC2 instance or RDS database deletion. Or it can be a simple cron – run this code X times per X periods of time.
As we need post match numbers and analytics it is enough to collect data once a day anytime after all the games of that particular day has ended. 3AM is perfect timing I think. So we will create a trigger for our Lambda to execute once a day at 3 AM.
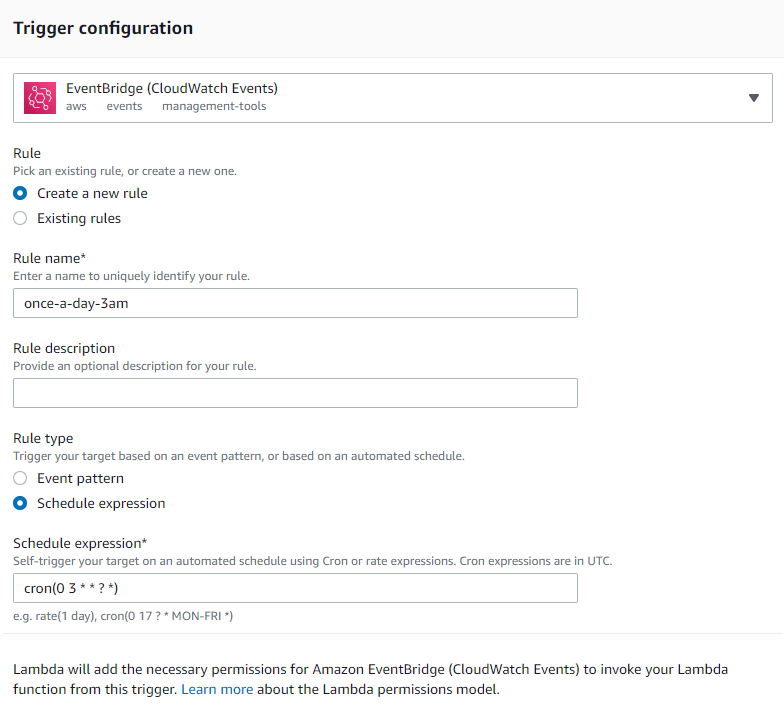
Remember that cron expressions are in UTC and pay attention to the fact that Lambda will add necessary permissions to execute the code on a schedule.
With this, we are ready to collect data on daily basis!
Although, one more thing. When you create a Lambda, you create it with default parameters. Some of those parameters are Memory – in simpler words, power of the compute capacity that will be given to the Lambda – and Timeout – amount of time Lambda will be running, maximum is 15 minutes. So, by default, Memory is 128MB and Timeout is 3 seconds. This is done in order to avoid unnecessary costs that Lambda may cause by hanging somewhere in running state.
The thing is, 3 seconds is not enough to collect all the data, our function needs a bit more. I’ve set-up a Timeout of 2 minutes – this is more than enough to get the data and upload it to S3.

Cost
Now you are wondering: “Okay, it is cool and awesome, but how much will it cost?”. Well, nothing. Until we aren’t dealing with heavy machinery AWS allows us to play with small things for free. Attaching some screenshots from AWS Calculator.
S3. Our dataset is pretty small, we will never exceed 50MB in storage. As we will be updating this dataset once a day – it is 30 PUT requests per month and let’s assume we will be downloading this data 3-4 times a day, which is 120 GET requests per month. And here is an estimate with these numbers doubled (just in case).

Lambda. We will run our function once a day for 2 minutes (120000 ms) or less with 128MB allocated.

OH, NO!!!! I’m such a liar! You will have to pay 0.01 USD. BUT! Only if you have already used a free tier (1 million requests per month and 400,000 GB-seconds of compute time per month) – and I am pretty sure you didn’t XD.
Conclusions kinda
Don’t be afraid to play around with new technology (even if they ask your credit card number during registration process) and explore it’s capabilities. As you can see, it is possible to create something small yet working, pay nothing for it and learn new skills.
Photo by Nelly Volkovich on Unsplash