
It’s been a long time since my last article, but finally I have something to share.
Last two months were real hell for me – we agreed on a short-term project that supposed to be easy and quick, but it ended up as always – with famous quote about programmer’s credo: “We do these things not because they are easy, but because we thought they were going to be easy”. Few weeks of work after hours, hundred pages of documentation, but we did it. And in this series of posts I am going to tell you what we did.
So, the project was to build a data lake for a client that has no clue about the cloud (yes, in 2021 it is still possible). As we are modern people and always intent to use the latest tech in our solutions we decided to build a completely serverless data lake. We did it. And now I am going to tell you how we did it.
Security
As we are dealing with data our first concern was security. In order to create a secure cloud environment we decided to use Operational Best Practices for CIS AWS Foundations Benchmark v1.3 Level 2 and implemented almost all of them. The Prowler score (a security tool to perform AWS security best practices assessments, audits, incident response, continuous monitoring, hardening and forensics readiness) we’ve got was 92% (few points lost because of some manual temporal changes we added in according to specifics of the project). Prowler is a really great open source tool and I recommend you to check your cloud environment with it (or you can set up AWS Config and Security Hub in order to constantly monitor all the settings). Link to Prowler.
Also we enabled AWS GuardDuty, AWS Config and AWS Security Hub in order to have more sensitive things under control and continuous monitoring. Getting high score also includes creating secure roles, groups and users with the policy of minimum permissions, what also has been done. And few things more. Won’t go into details here, because I might get lost – security on such a detail level is still novelty for me.
Architecture
So, how does the data lake without servers look like? We have a data-center that currently collects and guards all the data. First step is to set up a process of transferring data to the cloud. This can be done easy way (AWS Database Migration System) or not that easy way (bash scripts with aws-cli that upload the data to S3).
In S3, we are going to create 3 buckets, each of them responsible for different data “zones”:
- RAW (ingest zone, a place where all the raw, unprepared data gets dumped to)
- PREPARED (a place with previously preprocessed data, some basic clean-up, transformation to more optimized data format etc.)
- TRUSTED (zone, where clean and ready to consume data resides)
Next we will add crawlers for each zone to “read” files in S3 buckets and add metadata to our Glue Catalog. Once we have our crawlers, the next step will be to configure Glue Job to move the data between zones, to clean and optimize it during this process. When our pipeline is ready we will be able to query the data using Athena.
In the end this is what we end up with:
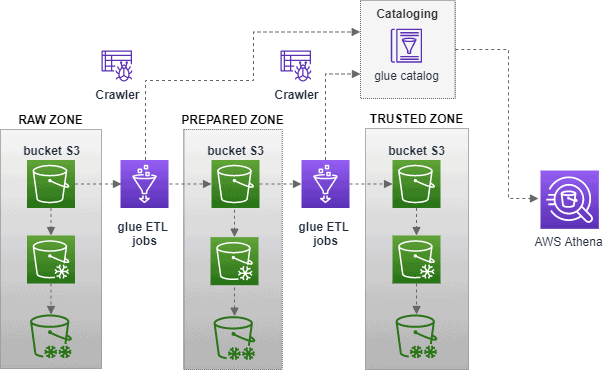
Sounds easy, obvious and kinda few hours of work, but never underestimate the dirtyiness of the data.

Terraform
For not that small and any other bigger projects in the cloud it is much better to use an IaC (Infrastructure as Code) tool – you will thank me later. Terraform is one of those. In the form of declarative configuration files you can write all your infrastructure and mess it up whenever and however you want – you will always be able to rollback to correct version without spending hours in deleting and recreating resources.
Terraform has a really clear and wide documentation with tons of examples of cloud resources and a huge community that continuously works on new modules.
AWS Services used in the project
S3 and S3 Glacier
As the foundational storage solution for the data lake was decided to use S3 as it is kinda obvious – it stores everything: structured, unstructured and semi-structured data. Music, documents, logs, DB extracts – all goes into S3. We used a lot of custom modules in this project. Here is an example that might be useful (we didn’t use this exact module)
Also we applied a lifecycle rules for the S3 data – after 30 days to Glacier, after 180 – elimination. Depending on each case this numbers can be adjusted. Even though S3 storage is really cheap, when we talk TBs of data these kind of transitions can save a bulk load of money.
Glue Crawlers
Once we have our data in S3 we can make it SQL-consumable with the help of crawlers, Glue Catalogues and Athena. Bit first things first. Crawlers.
These guys analyse objects in S3 using a built-in set of classifiers and add metadata about this object to a Glue Catalog. Crawlers are capable of recognizing CSV, JSON, TXT, GROG, they can also crawl DynamoDB, Aurora, MariaDB, SQl Server, MySQL, Oracle, PostgreSQL and even MongoDB.
Even though crawlers are quite intelligent it is better to not give them a lot of freedom. There are two good approaches:
- 1 crawler per 1 table with custom classifiers when that is necessary
- 1 crawler per entire data store without the possibility to update schema of the destination table as the table has a solid and previously defined structure.
With Terraform any of this approaches is easy to implement. For the first one you just create a list of tables and then create a loop to launch a crawler per table.
Or you just define all the tables of your catalog in Terraform code. Yes, this one is a bit longer and boring, but saves you from the future headaches.
Glue Jobs
About ETL jobs we can talk eternally: all the specifics, best practices etc, but in this scenario we used them only to make a transformation from CSV to parquet in order to optimize data for better consumption in Athena and that’s it.
Glue is a serverless ETL solution with which you don’t need to provision resources for data transformation operations – just write a script, assign few virtual machines (something approximate that will do the job, can be changed later) and you’re done.
Also, Glue Jobs are really easy to create with Terraform. You create a resource for the job itself, write a script with the logic, add additional resource in order to upload that script to S3. Done. Examples below.
Glue Catalog
Crawlers and Jobs do not make any sense if they don’t have sources and targets with clear definitions. Glue Catalog is a virtual DB – you have a list of databases which are a collection of tables that are defined manually or using crawlers. It doesn’t have functions and stored procedures, but AWS does have Lambdas for that kind of operations XD.
Workflow and Events
As we are modern lazy people we want all our pieces to move automatically and avoid any manual work. For this Amazon created Glue Workflows, but we decided to go old-fashioned way – with Events (CloudWatch and S3) and Lambdas.
And even though it looks scary on the scheme, I didn’t have to code every element from here – just the ones that are not repetitive. All the others I had to declare just once. Beauty of IaC.
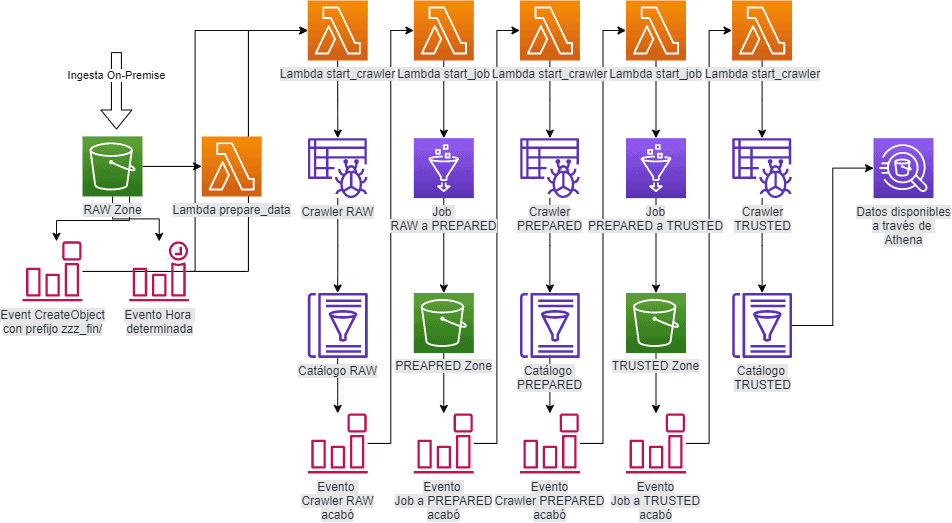
So, what’s happening here. First we have an ingest zone where all our dirty data arrives from different sources. We have two optional triggers for here: time schedule and S3 specific event – when there is an upload to the directory “zzz_fin” it triggers the next process. So the ingestion scripts can use just one additional line to kinda say “we’re done uploading, it’s your turn guys!”
Previous events trigger Lambda that starts a corresponding crawler. That’s it. All the Lambda does is to start a crawler. Nothing more.
Once crawler is done crawling, it updates data catalog and fires an event. This event we also create with Terraform XD.
The previous event triggers a Lambda that starts a Glue Job to move and transform data. After that is done Glue Job shoots another event saying “we’ve successfully moved data between the zones we can start again”. And the process repeats till the cleaned data gets to the trusted zone.
Also, few considerations. Each rule has to have a target – when event happens, then something else happens. Another thing, read carefully AWS documentation. If you compare “state” value in previous two gists you will notice for crawlers it is “Succeeded” and for job it is “SUCCEEDED” – those are two DIFFERENT THINGS! I wasted few neuron cells before realising that. Don’t repeat my mistakes 😉
Conclusions
This is a very brief explanation of implementing a data lake on AWS. Also it doesn’t pretend to be the best one. It just lays down a ground work from which it can evolve in a really huge and powerful system. It surely lacks some additional logic for retries and handling of failed operations, but the main goal here was to create a foundation. And the goal was achieved.
Hopefully, it gives you some ideas in regards to operations with data on the cloud and moreover it gives you a perspective for the power of IaC. As you might notices I haven’t used any screenshot from AWS Console, because once you start working with Terraform it becomes a past century XD.
Can you share code repo link?
Oh, there is no repo. These are just gists with code examples, you will have to make your own repo 🙂
How to resolve the Lake formation issue for Crawlers on Catalog?
Honestly, I have no clue. I guess a better person to ask for it will be mister Google 😀
do you have modules/aws-s3-bucket
and also module.dl_kms
to share with us?
It is hard for us to ramp up.