
Pandas is cool and awesome, but what if you just need a small transformation of data, a punctual change and you don’t want to install heavy things on your server? Or maybe you just launching Lambdas (or any other serverless functions) that have limited capacities in resources? In such scenarios, it is much better to stick to Python’s standard library and not load it with unnecessary stuff.
Also, knowing a few tricks will make your code much more readable and help you avoid redundancy. So, in this article, I will show you a few data manipulation tricks using only a standard library that might save you time and resources.
We will work with the following .csv file as it is the most common format – a dummy shopping cart in a clothing store (you can just copy-paste it):
name,color,category,price,quantity
t-shirt,black,top,20,1
pants,white,bottom,50,1
blazer,yellow,top,100,1
t-shirt,red,top,15,2
t-shirt,orange,top,25,1
sneakers,white,footwear,100,1
bracelet,green,accessories,5,31. Function enumerate()
It is not about data manipulation yet, but just a cool thing to consider. The function works like a normal iterator, but it just adds an index to every iteration. It comes in handy especially when reading from files as it allows to track the line numbers. Try this out:
In the end, those 2 lines do not make a huge difference in performance, but it looks more aesthetic and you avoid loose variables here and there.
2. Reading .csv files without pandas
Reading .csv files with standard file reader in Python might get complicated in some cases as it will return the content of the file as the string and we will need to add additional steps to handle that huge string. For these cases it is quite convenient to use module csv. This reader gives you option to select a delimiter, quotechar, escapechar and few other options to make .csv import much easier. Try this:
And you will get the following output:
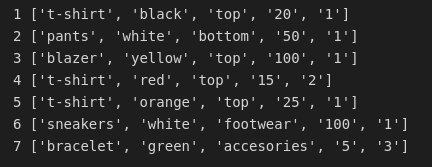
One thing to take into account from this output is that every value from a column will be considered as string, so if you want to perform some operations on those values you will have to adjust the types.
3. Collections
For the data manipulations part, we will use a module collections. From the documentation: “This module implements specialized container datatypes providing alternatives to Python’s general-purpose built-in containers, dict, list, set, and tuple.”
If you have a dataset with clothing items and want to find the total price of t-shirts or count how many different t-shirts you have there, how would you do that? A class Counter() will help.
3.1. Counter
Check out the snippet below and see the difference. 1st version looks much better than the 3rd one, even though both are valid and do the same thing.
Also Counter() has a few handy methods like most_common() and total() (total() available in Python 3.10 only).
>>> total_clothes.most_common(3)
[('jacket', 100), ('t-shirt', 55), ('pants', 50)]
>>> total_clothes.total()
220Another cool thing that can be done using Counter() is finding the most common words in a text or the most common character in a word. Let’s start with an easy one:
>>> Counter('abracadabra').most_common(3) # that's an example from Python docs actually
[('a', 5), ('b', 2), ('r', 2)]Now let’s use a common dataset for words count – Shakespear’s ‘King Lear’. This dataset will be in my repo for articles, folder /data. Check the following little program:
And here we have all our words counted.
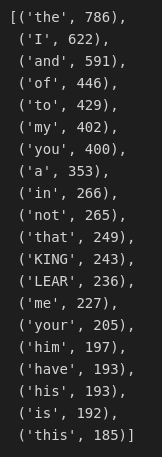
What we have done here? We read the file line by line, removed all the punctuation from each line (about this later), split that line into words, created a Counter() for the words in each line and in the end added a counter per line to a total counter. Also we can check how many words in total are there:
>>> count_words.total() # only if you have Python 3.10
27762Obviously, NLP libraries will tackle this more effectively, but hey!, it is pretty awesome to know you can do that with standard library and just few lines of code.
3.1.1. Removing all punctuation from the string
This one I have found while writing the program to count words XD. Honestly. I was really looking for a regex pattern to apply for this transformation, but apparently standard library and string module already has quite a simple solution.
line = line.translate(str.maketrans('', '', string.punctuation))What do we do here?
str.translate()– returns a copy of a given string in which each character has been replaced using mapping (translation) tablestr.maketrans()– creates a translation table, you can read more in detail how exactly it works in Python docs, but for this particular example we have to know that the third parameter is always mapped toNone, or, for those like me, that need plain language to understand things – it removes any character specified in the third argument.string.punctuation– predefined list of all punctuation characters. You can check that list in docs or simply by running:print(string.punctuation)
So basically we get a new line, but without punctuation and without regex. Now let’s get back to collections.
3.2. defaultdict
Now, if you don’t want to add up different values for same keys but just map it to see what is going on there – defaultdict will take care of it:
And again as you can see, with regular dict that won’t work. Or you will have to write that ugly workaround and check if a key exists.
The first argument of the defaultdict, default_factory, sets up a default value for each key. In our first example it was a list. But if we pass an int there, we will be able to use it as a counter too. Try the following:
But the usage of the Counter() is much wider, so bear this in mind. For example, with defaultdicts you cannot perform the sum, like we did with the counters when counting words.
3.3. deque
Imagine you have to keep a history of N last elements or N last lines of the file, deque is a perfect solution for this. Now you can run window functions without turning into complex SQL queries. Rather ugly example, but still a food for thought. Imagine you have a dataset with the results of a given football team and you want to calculate their form in recent matches. Dummy dataset is available in data folder. Check this out:
And the result:
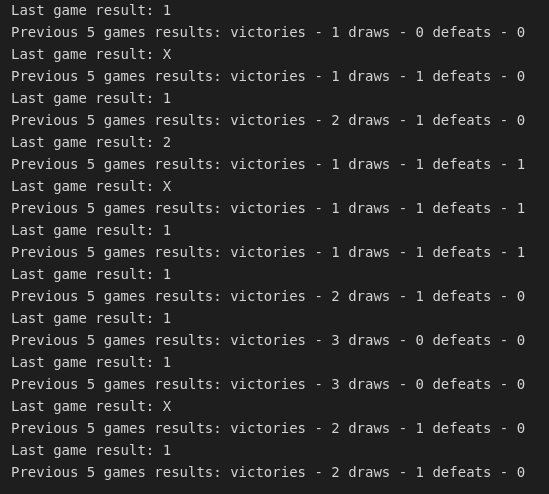
Again, this one lacks some tuning, but I hope you get a general idea.
Last words
We’ve got so used to all these fancy packages that we forget the standard library completely. And standard library still got some aces in its sleeve. So the next time you need to perform a quick data manipulation with 0 dependencies on external packages try some of those tips.
Hope you find it useful! Cheers!
Photo by Andriyko Podilnyk on Unsplash